
Data preprocessing in Python
About the project
The objective of this project is to predict the revenue-related metric using the dataset provided by a client, an ad agency. This project has two phases. Phase I focuses on data preprocessing and exploration, as covered in this report. We shall present model building in Phase II (link).
The project is an example of data preprocessing in Python.
Goal
This project aims to prepare the data for the modelling process. The project includes three sections:
- Describing the dataset and its attributes.
- Data pre-processing
- Exploring each attribute and their inter-relationships.
Data
This dataset contains online advertising data where the target feature is a revenue-related metric and the descriptive features are various advertising metrics and characteristics.
Outcomes
The project provided an overall understanding of the dataset and its attributes via visualisations. In addition, the dataset was prepared appropriately for the modelling phase.
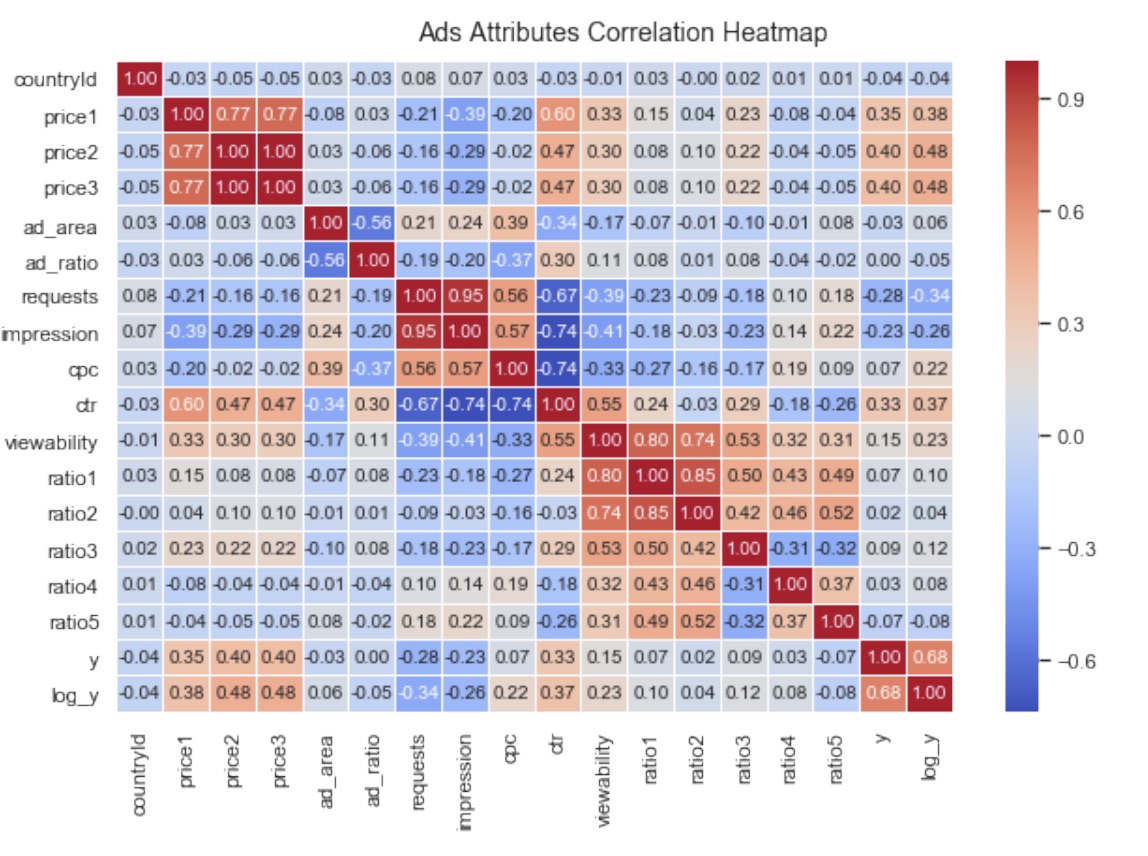
Limitations
The project can benefits from marketing expert knowledge regarding some of the attributes such as ratio1, ratio2, ratio3, etc.
What I’ve learned from this project
- The data preprocessing process is not linear; each of the steps of the process has be revisited multiple times during the project.
- Expert knowledge matters: The project presented myself with an exciting learning opportunity; I have learned so much more about Google ads. However, expert knowledge will add more layers to the understanding in a fraction of the time spent.
The projects covers various steps of the data preprocessing including:
- Dealing with continuous and categorical data.
- Data normalisation.
- Dealing with missing values.
- Data exploration using univariate and multivariate visualisation.
- Creating new variables.
You can download the report here.
The project demonstrates the ability to work with Python libraries including Matplotlib, NumPy, Pandas, Seaborn and SciPy