
MapReduce
About the project
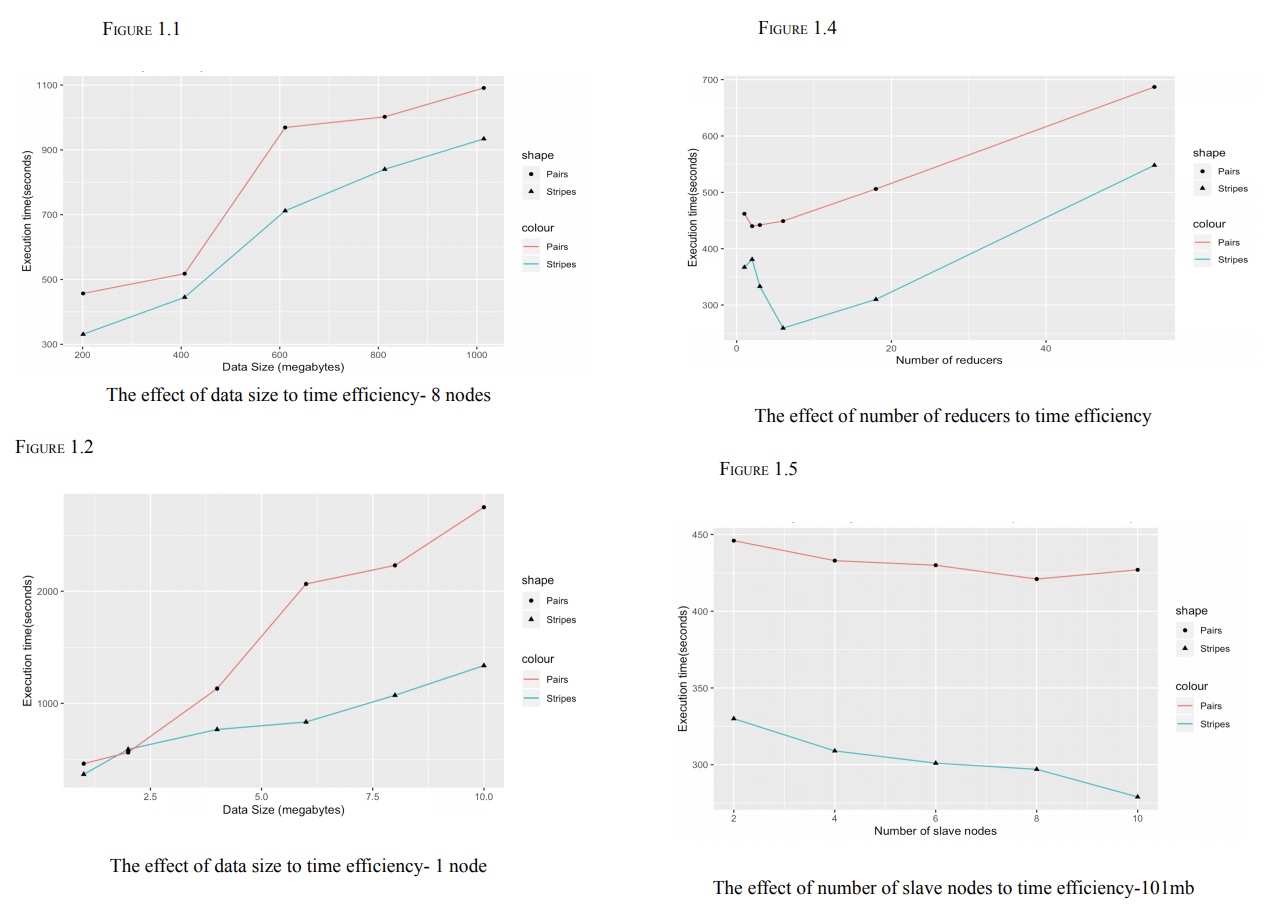
The project investigated the scalability efficiency of the two popular words co-occurrence algorithms: “pairs” and “stripes”. The project was an implementation of MapReduce in Java.
Goal
The project compared the two words co-occurrence algorithms: “pairs” and “stripes” in term of the time efficiency. The purpose of the project was to determine which approach is better for scaling.
Data
The project used the Common Crawl dataset, made available by Amazon S3.
Methodology
The algorithms were tested against variables including: data size, number of mappers, number of reducers and number of slave nodes.
The context of co-occurrence is defined as : the closest 2 words in the same sentence.
Outcomes
Overall, the “stripe” approach performs better than the “pairs” approach in all the testing environments.
What I’ve learned from this project
-
Choosing the best algorithm: In order to maximise time efficiency and minimise running cost, we are required to understand not only which algorithm is better, but also how each algorithm thrives in practical context.
-
Working with AWS: The best way to learn a new tool is emerging yourself in the practical environment with curiosity. In addition, the learning process benefits from making lots small mistakes, then recover/learn from those errors quickly.
You can download the project report here here
You can access the Java codes here. ( I am working on providing you with the source codes.)
The project demonstrates the ability to work tools including
- A complete MapReduce implementation in Java with some components of Natural Language Processing.
- Amazon EMR Management.
- Amazon S3 bucket, Eclipse,Apache Hadoop, Maven.